jstorm,深入解析JStorm——实时流式计算框架的强大与稳定
JStorm是一个分布式实时计算引擎,类似于Hadoop MapReduce系统。它是由阿里巴巴基于Apache Storm使用Java语言重写和改进的开源项目。JStorm在性能、稳定性和可扩展性方面进行了许多优化,适用于大规模的实时流数据处理。
主要特点1. 高吞吐量与低延迟:JStorm能够处理大量数据,并且具有较低的延迟,适用于需要快速响应的应用砛n
深入解析JStorm——实时流式计算框架的强大与稳定

随着大数据时代的到来,实时流式计算在处理海量数据方面发挥着越来越重要的作用。JStorm作为一款开源的分布式实时计算框架,因其强大的性能、稳定的运行和易用的特性,受到了广泛关注。本文将深入解析JStorm,帮助读者全面了解这一实时流式计算框架。
一、JStorm简介

JStorm是阿里巴巴中间件团队基于Storm重写的实时流式计算系统框架,采用Java语言实现。JStorm继承了Storm的优点,并在此基础上进行了诸多改进,如解决了Storm的Nimbus单点问题,提高了系统的稳定性和性能。
二、JStorm架构

JStorm的系统架构主要包括三个进程:Nimbus、Supervisor和Worker。
Nimbus:负责Topology提交、向Zookeeper写入元信息及任务调度。
Supervisor:根据Nimbus的任务调度结果启动/停止工作进程Worker。
Worker:JStorm任务执行者,其中的Task对应拓扑模型的一个component。
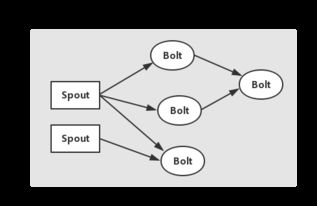
三、JStorm拓扑模型

JStorm的拓扑模型类似于Hadoop MapReduce,由Spout、Bolt和Topology组成。
Spout:消息源,用于生成消息。
Bolt:消息处理单元,对消息进行处理。
Topology:由Spout、Bolt和流连接组成,表示整个计算流程。
四、JStorm优势
JStorm具有以下优势:
易开发性:JStorm接口简易,只需按照Spout、Bolt及Topology编程规范进行应用开发即可。
扩展性:可以线性的扩展性能,配置并发数即可。
容错性:出现故障worker时,调度器会分配一个新的worker去代替。
数据精准性:JStorm内置ACK机制,确保数据不丢失。还可以采用事务机制确保进一步的精准度。
实时性:JStorm不间断运行任务,且实时计算。
五、JStorm应用场景

JStorm适用于以下场景:
实时计算:可实时数据统计,实时监控。
消息转移:流处理完消息后,可以定向的将结果存储到其他消息中间件中。
RPC请求:提交任务就是一次RPC请求过程。
六、JStorm与Storm对比
JStorm与Storm在架构和功能上有很多相似之处,但JStorm在以下方面进行了改进:
Nimbus HA:解决了Storm的Nimbus单点问题,支持自动热备切换Nimbus。
更细粒度的资源划分:JStorm从CPU、MEMORY、DISK和NET四个维度进行任务调度,同时不存在任务抢占问题。
可定制的任务调度机制:JStorm的任务调度目前也可定制。
更好的性能:通过底层ZeroMQ和Netty使JStorm具有更好的性能,同时具有更好的稳定性。
解决了Storm的雪崩问题:通过Netty和disruptor机制实现RPC保证可以匹配的数据发送和接收速度避免雪崩问题。
JStorm作为一款优秀的实时流式计算框架,具有易用、稳定、高性能等特点。在处理海量数据、实时计算等方面具有广泛的应用前景。本文对JStorm进行了深入解析,希望对读者有所帮助。




